Я участвую в проекте по обработке данных. Предыдущая версия использовала MS Sql Server для своей работы, поэтому анализ работы системы сделать было достаточно просто, можно было обойтись и простым t-sql скриптом или, если нужно было графическое представление, то можно было использовать Reporting services. Сейчас же, для того компонента, которым я занимаюсь, никакие СУБД не используются, поэтому какие-то выводы можно делать исключительно по логам. Поэтому даже был сделан отдельный структурированный лог в csv формате обо всех важных событиях, произошедших в системе. К примеру, к нам приходит много файлов, поэтому для каждого из этих фалов, этот лог содержит упрощённо 3 записи: файл найден, файл отправлен на обработку, файл обработан. Как то у Ярослава возникла идея попробовать язык R, чтобы нарисовать какие-нибудь интересные аналитические графики. Меня идея заинтересовала, я скачал книгу и впал в ступор. В общем и целом, язык этот мне не понравился (можно сказать не осилил:)). Но месяц назад в очередном порыве изучения clojure, у Алекса наткнулся на упоминания о проекте incanter. Лучше всего его описали сами авторы:
Incanter is a Clojure-based, R-like platform for statistical computing and graphics.
В этой статье я попробую рассказать, как я, человек знакомый с clojure только по статьям/книгам/скринкастам, использовал incanter для построения интересных, на мой взгляд, графиков работы нашего приложения.
В начале надо разобраться как работать с этим всем хозяйством. Если Вы знакомы с clojure, то тут мне даже объяснять не надо, если нет, лучше всего прямо с сайта скачать один jar файл (а если у вас win или osx, то есть нативный файл), в который авторы собрали все необходимые библиотеки. Если его запустить, то мы увидим REPL (read-eval-print loop), куда мы можем вводить свой код и он будет сразу выполняться.
Приступим, и первой командой подключим все библиотеки, которые будут нужны нам на протяжении работы:
(use '(incanter io core datasets charts))
Clojure это лисп, поэтому синтаксис у неё очень простой (стырено из замечательного комикса):

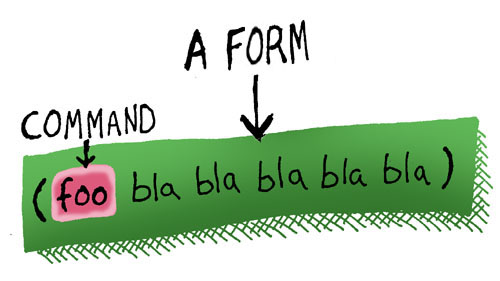
Т.е. скобочки и префиксная нотация, ничего сложного, но непривычно :)
Теперь нам надо загрузить данные из лог файла, это достаточно простой csv файл с колонками FileName, FileType, Time, Event. В терминах incanter мы будем работать с dataset и следующей командой мы легко и просто загрузим все наши данные в переменную data.
(def data (read-dataset "history.csv" :header true))
Я не говорил, но думаю даже те, кто не знает о лиспах, догадались, что в clojure динамическая типизация (но если хочется, то типы можно указать). Т.о. функция read-dataset прочитала данные их нашего файла в структуру data. Через имена колонок мы можем получить наши данные. Однозначный зачёт. Кто пользуется repl увидели строку #'user/data, не очень информативно, но repl выводит на экран все toString возвращаемых функцией объектов. Поэтому, например, после первой строчки мы увидели nil, так как она ничего не вернула.
Как же нам увидеть, что на самом деле там сохранилось. И тут разработчики incanter молодцы, они написали функцию view с помощью которой можно получить графическое представление всех структур, используемых в этой библиотеке. Для dataset это будет ещё одно окошко с swing табличкой, для графиков используется популярная swing компонента JFreeChart. Но я для графиков пользуюсь другой возможностью этой библиотеки, а именно функцией save, которая позволяет сохранить график в картинку на диске. Если мы до этого в переменную plot (будет дальше по тексту :)) загрузили график, то мы можем сохранить его следующей командой:
(save plot "plot.png" :width 1000)
Кстати, Вы заходили на сайт библиотеки? Если нет, то спешу обрадовать, там много хороших статей, а также есть прекраснейшая api документация с кучей примеров для каждой функции. Вы так же могли заметить, что в функцию передаются параметры :header, :width, это всё потому, что clojure поддерживает переменное число аргументов у функции, поэтому мы можем передать туда дополнительные опции. Термы начинаемые с двоеточия это keywords, означают то же что и написано, такие улучшение string константы :) (лучше почитать у умных людей про них, в лиспах это называется symbols).
Приступим к созданию первого графика. Он будет простым. Как я выше написал, у нас есть файлы и они имеют тип. Давайте посчитаем сколько каждого типа файлов было обработано нашим приложением. И следующей командой отберём только те строки, которые соответствуют событию PROCESSING_SUCCEEDED. Для этого мы воспользуемся алиасом $where для функции query-dataset (так как он проще по синтаксису). Ему необходимо передать условие, по которому будут отобраны строки и сам датасет. Условие простое, мы используем keyword соответствующий колонке EventType и строку "PROCESSING_SUCCEEDED", т.е. будут выбраны только строки, у которых в колонке стоит это значение. Синтаксис не сложный и в api этой функции можно увидеть больше примеров.
(def processed ($where {:EventType "PROCESSING_SUCCEEDED"} data))
Все функции работы с датасетами возвращают новый датасет, поэтому мы его помещаем в отдельную переменную, но можно и объединить в цепочку вызовов. А теперь просуммируем все значения сгруппировав по типу. Всё это напоминает sql, только перевернутый, префиксный :) Воспользуемся ещё одной отличной функцией $rollup. Как Вы надеюсь помните, clojure это функциональный язык, поэтому он поддерживает функции высших порядков. Это означает, что любая функция - это полноправный объект, который можно передавать в другую функцию или возвратить из неё. $rollup этим и пользуется. Он получает функцию для группировки значений, это может быть ваша собственная или вы можете передать keyword, соответствующий предопределенным (полный список можно подсмотреть в api), это может быть например функция минимума, или в нашем случае - функция суммирования. Вторым параметром идёт keyword для колонки, в которую будут помещены значения, и напоследок keyword колонки, по которой будет производится группировка и сам dataset.
(def processedFileСonters ($rollup :count :FilesCount :FilesType processed))
Мы получили нужный нам набор данных. Теперь воспользуемся функцией bar-chart, чтобы отобразить столбиковую диаграмму (как я писал выше, к результату этой функции необходимо применить функцию view, если вы хотите увидеть результаты, или save, если хотите сохранить результат в виде картинки). Функция bar-chart принимает имена двух колонок с значениями и именами столбцов и кучу опций, одной из которых является :data, куда мы передаём наш датасет (правда ещё предварительно отсортировав).
(def plot (bar-chart :FilesType :FilesCount
:x-label "File type"
:y-label "Files count"
:title "Files count by type"
:data ($order :BundleClass :asc processedFileСonters)))

Получилась хорошенькая гистограмма и как мне кажется, код и процесс написания достаточно прост. Покажите мне ещё один такой язык с такой библиотекой? Ну разве что ещё linq тоже удобен для работы с данными.
После первой диаграммы я освоился и стал их делать уже быстро. Поэтому сейчас покажу ещё пару диаграмм и буду освещать только новые функции, которые использую. Теперь мне захотелось добавить рядом ещё одну колонку, которая бы содержала число пришедших файлов, так как оно может отличаться: к нам приходят и пустые файлы, а обрабатывать их бессмысленно. Для этого нам надо расширить полученный в предыдущем пункте dataset. Добавим строки, которые содержат числа для тех же типов, но уже с количеством для найденных файлов. И третью колонку, которая соответствуют типу события: обработан/найден. В начале определим функцию для получения по dataset'у нашей матрицы со счётчиками для типов, просто обернув приведенный выше код в функцию. В начале идёт имя функции, в квадратных скобках переданные аргументы, а потом код, который мы уже видели.
(defn fileConter
[type data]
($rollup :count :FilesCount :FilesType ($where {:EventType type} data)))
Теперь воспользуемся функциями conj-cols, conj-rows. Первая объединяет датасеты вертикально, т.е. добавляет колонки, вторая горизонтально, увеличивая число строк. Т.о. мы к датасетам, полученным из наших функций добавим ещё третью колонку содержащую повторяющийся тип события. А потом их объединим. Ах да, ещё воспользуемся col-names, чтобы добавить имена колонок.
(col-names
(conj-rows
(conj-cols (fileConter "PROCESSING_SUCCEEDED" data) (repeat "Processed"))
(conj-cols (fileConter "DETECTED" data) (repeat "Detected")))
[:FilesType :FilesCount :Event])
Для того, чтобы данные отображались отдельным столбиком, необходимо добавить лишь опцию :group-by :Event при вызове bar-chart

Супер, не так ли?! Продолжим. Теперь тоже самое нарисуем на временной шкале, т.е. сколько в каждый момент времени было обработано файлов (мы их обрабатываем пачками, поэтому буду пики). Даты у нас представлены строками, а библиотека работает с миллисекундами, поэтому нам надо сделать преобразование. И будем делать это через java, с помощью SimpleDateFormat.
И вот сейчас будем рвать мозг. До этого префиксная нотация была мала заметна, так как в java и др. языках мы имя функции тоже пишем в начале. Одной из главных фич clojure является великолепная поддержка работы в java. Вот функция, которая делает нужное нам преобразование через java, но в синтаксисе clojure. Как вам?
(defn as-millis
[date-as-str]
(.getTime (.parse (java.text.SimpleDateFormat. "yyyy-MM-dd HH:mm:ss") date-as-str)))
И так, как бы нам преобразовать все даты? Очень легко, используем ещё одну прекрасную функцию $map, так же как $rollup она принимает функцию преобразования, имя колонки и датасет. А вторым шагом будет применение $rollup, т.е. для каждой даты посчитаем сколько файлов было помечено как обработанные. Вот так формируем наш датасет.
(def timeline ($rollup :count :FilesCount :Time
(col-names (conj-cols
($map #(as-millis %) :Time data) ($ :FileName data)) [:Time :FilesCount])))
Ах да, #(as-millis %) это мы так делаем лямбда функцию, которую передаём в функцию $map.
Теперь сделаем диаграмму, тут всё ещё проще.
(time-series-plot :Time :FilesCount
:x-label "Date"
:y-label "Files count"
:title "File processing history"
:data timeline)

Чем больше я работал с этой библиотекой, тем более довольным я становился! :)
И теперь последний, более сложный пример, посчитаем среднее время обработки (начиная с даты прибытия и до даты, когда он был обработан, так как на обработку он посылается не сразу, а время обработки и так высчитывает в отдельную колонку самим приложением). Сделаем ещё два датасета.
(def detected ($where {:EventType "DETECTED"} data))
(def processed ($where {:EventType "PROCESSING_SUCCEEDED"} data))
И функцию (использующую предыдущий код), чтобы перевести время для разных датасетов.
(defn timings
[data column]
(col-names (conj-cols ($ :FileName data) ($ :BundleClass data)
($map #(as-millis %) :Time data))
[:FileName :BundleClass column]))
С помощью её, построим табличку, которая содержит колонки: Имя файла, Тип файла, Когда пришёл, Когда был обработан. Сделать это можно с помощью функции $join, она умнее conj-cols и не просто достраивает сбоку, а работает между двумя датасетами как реальным СУБД'шный join.
(def filesTimings
($join [:FileName :FileName]
(timings detected :DetetctedTime)
(timings processed :ProcessedTime)))
Дальше ещё проще, будем снова использовать пару $map и $rollup. С помощью первой рассчитаем разницу в минутах между колонками. А вторая высчитывает среднее (:mean) для каждого типа файлов.
(bar-chart :BundleClass :ProcessingTime
:x-label "Bundle class"
:y-label "Average file processing"
:vertical false
:title "Average file processing by type"
:data ($order :BundleClass :asc
($rollup :mean :ProcessingTime :BundleClass
(col-names
(conj-cols ($ :BundleClass filesTimings)
($map #(/ (- %1 %2) 60000)
[:DetetctedTime :ProcessedTime] filesTimings) )
[:BundleClass :ProcessingTime]))))

У меня ещё куча идей, какие графики можно сделать, но пост уже и так большой. А мне хотелось бы напоследок немного пофилософствовать. До этого с clojure я имел лишь теоретический опыт, а с incanter вообще не был знаком. В результате меньше чем за полдня сегодня я соорудил три прекрасных графика. Причём я очень доволен кодом. Он компактный, в сумме менее 70 строк и при этом хорошо читаем. И что немаловажно, на протяжении всей статьи, я постоянно какие-то куски с лёгкостью выдирал в отдельные функции и переиспользовал.
Теперь пофилософствуем. Зачем вообще все эти графики. Моё мнение, почерпнутое у умных людей и проверенное опытом: если вы разрабатываете приложение по обработке данных, то надо постоянно анализировать, анализировать данные, которые к вам приходят, анализировать то как ваше приложение работает с этими данными. Приведу пример. В своё время, разрабатывая предыдущую версию приложения, Ярослав предложил проанализировать те данные, которые должны были к нам приходить. Делали мы это с помощью Ruby и Excel. Ruby помогал собрать статистику, а с помощью Excel рисовали всякие pivot'ы. В результате было обнаружено большое, независимое подмножество данных. Благодаря чему, оно обрабатывалось отдельно и это привело к значительному ускорению обработки инкрементальных обновлений. Это было настолько классным решением, что в новой версии продукта его тоже используют. Кроме того, старое приложение обрабатывало этот набор не намного медленнее новой версии, которая делается с помощью мего супер тула.
Цикл "маргинальных технологий" я придумал с целью :) Я пишу, только о том, с чем столкнулся, о другом мне писать сложно. Так вот. Где-то читал стенания одного человека, что он ушёл из компании, потому что ему не давали писать unit тесты. Это просто смешно. Поэтому и решил сделать этот цикл, чтобы показать, что интересные технологии можно использовать даже там, где им казалось бы не место. Например статья про hg рассказывает именно о плагине hgsubversion, чтобы показать, что даже если вы не можете использовать напрямую на работе hg, это не значит, что вам не дают его использовать. Я использую локальный hg в связке с нашим центральным subversion репозиторием и доволен, пока остальные жуют кактус :) Это статья, о ещё одной технологии, которую можно использовать в любом проекте по обработке данных. Понятное дело на clojure вам никто не даст писать код в продакшен, даже scala аккуратно используется в реальных проектах, да и то по большей части во всяких стартапных твиттерах. Но вы можете использовать clojure в связке с incanter, чтобы проводить анализ. На это дело обычно нет ограничений, но как я выше написал, такой анализ очень полезен, а incanter делает его простым для реализации.
btw, я взял посты по метке Clojure для http://fprog.ru/planet/. Если вы будете писать про другие ФЯ, то можно договориться о какой-то специальной метке для прокидывания в планету - просто напишите мне на email
ОтветитьУдалитьЗдраствуйте Алекс,
ОтветитьУдалитьда планы и идеи есть уже давно. И думаю будут появляться, хотя и не слишком часто. Но не знаю насколько они потянут на добавление в планету, так как в прекрасный мир функционального программирования я проник не давно (во многом благодаря вам: alexott.net/fprog.ru, за что огромное спасибо), да и пишу я не так чтобы хорошо...
Но всё же добавил тег FP.
отлично! исправил метку, следующие посты попадут в ленту планеты
ОтветитьУдалитьВам спасибо!
ОтветитьУдалить"не очень нравиться", "и он сразу будет выполнятся"... Читатели, закончившие школу, могут усомниться в адекватности материала об этом функциональном языке, коль скоро материал этот написан с таким пренебрежением к языку русскому.
ОтветитьУдалитьСпасибо за замечание. Исправил и вечером ещё раз более внимательно перечитаю.
ОтветитьУдалитьПросто нет удачной unit test библиотеки для русского языка :)
Хочу себе такие комменты.
ОтветитьУдалить